Call for Participation
Stuttering is a speech impediment that affects around 1% of the world’s population. The funda- mental cause of the stuttering is still unknown, although multiple hypotheses exist, such as genetic problems, congenital factors, and structural and functional brain differences.
The impact of the stuttering on people who have such a problem could be on both social functioning and mental aspects. Stuttering hinders daily oral communication with speech repetition, prolongation, blocks, and secondary behaviors, such as body movements and facial grimaces. People who stutter (PWS) quite often feel stress, shame, and low esteem when their stuttering behaviors are exposed, which can cause them to fear speaking. To avoid those negative feelings, many PWS hold back from communication and even choose to self-isolate.
Stuttering is also a developmental speech disorder. Most PWS begin their stuttering in childhood, with an average onset of 30 months. Around 20% of them persist stuttering to adulthood. Therapeutic intervention for children who stutter is statistically more effective than for adults, which can increase the chance of full recovery. The importance of early diagnosis is self-evident.
However, compared with North American or Western European countries where the practice of speech-language therapists (SLP) has been evolving for quite some time, the related practices in Mainland China are still in their infancy, as there is no separate certification for speech therapists. Due to the lack of professionals, many families of children who stutter cannot receive timely diagnosis, thus delaying the recovery of their children from stuttering. While adding more professionals, automatic stuttering diagnosis can also meet the needs of some families.
When a person’s stuttering continues into adulthood, the chance of full recovery becomes very low. There is a high probability that stuttering will accompany them throughout their lives. To alleviate their communication barriers or, in a broad sense, eliminate social discrimination, relevant products need to be designed to be inclusive to meet their needs.
With the widespread popularity of smart home devices, and the rapid development of chatbot technology, e.g., Alexa and Chatgpt, voice-user interfaces have become indispensable tools in many of our lives. Although current Automatic Speech Recognition (ASR) systems can handle fluent speech well, they still pose a challenge for stuttering speech recognition. The reasons could be multifaceted, such as a lack of data or awareness of the need to develop systems for these people.
Motivated by the above points, we propose to organize the challenge – “Mandarin stuttering event detection and automatic speech recognition” (StutteringSpeech Challenge for short) in SLT2024. This will be the first challenge on Mandarin stuttering event detection and ASR.
Task Setting and Evaluation
The challenge comprises two tasks and open submission of papers on related topics:
- Task I Stuttering Event Detection: This is a multi-label classification task. Participants will be asked to develop models that are capable of identifying the stuttering events in short stuttering speech audio snippets. The five types of stuttering events that may appear in audio snippets are sound prolongation, sound repetition, character repetition, block, and interjection. Train development sets that contain audio snippets and their labels will be provided to the participants at the beginning of the challenge for the model development.
- Task II Stuttering Automatic Speech Recognition (ASR): The main goal of this Task is to advance the development of ASR systems that can deal with stuttering speech. Participants must devise speech-to-text systems that effectively recognize speech containing stuttering events into the clean text from which the stuttering event labels are stripped out. Train development sets that contain long-form stuttering speech audio and their text will be provided for the system development.
- Task III Research Paper Track: Participants are invited to contribute research papers that apply the stuttering speech dataset and evaluation framework in their experimental setups and analyses. This is an opportunity to explore and document innovative approaches and findings related to stuttering speech technologies.
For Task I, the submitted systems will be measured by stuttering event detection accuracy-recall, precision, and F1 on audio snippets in the evaluation set.
For Task II, the accuracy of the ASR system is measured by Character Error Rate (CER). The CER indicates the percentage of characters that are incorrectly predicted. Given a hypothesis output, it calculates the minimum number of insertions (Ins), substitutions (Subs), and deletions (Del) of characters that are required to obtain the reference transcript. Specifically, CER is calculated by
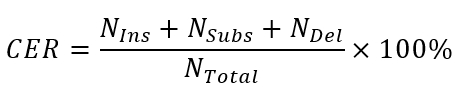
Where NIns , NSubs , NDel are the character number of the three errors, and NTotal is the total number of characters. As standard, insertion, deletion, and substitution all account for the errors.
For Task III, there are no specific evaluation metrics, and we welcome paper submissions for research using our stutter data.
Dataset
The data used in this challenge is meticulously gathered during 70 online voice chat sessions. The dataset captures two scenarios-dialogue and command dictation. Each recording session begins with around half an hour of interview by two native Mandarin speakers who are both PWS. Then, the interviewee was asked to read a prepared list of commands. The effective duration of the dataset is around 50 hours, encompassing a comprehensive collection of recordings from 72 distinct PWS-2 interviewers and 70 interviewees. The speaker numbers of train/development/test partitions can be found in Table 1.
| Mild | Moderate | Severe | Sum | |
|---|---|---|---|---|
| Train | 25 | 12 | 6 | 43 |
| Dev | 4 | 2 | 1 | 7 |
| Test | 14 | 3 | 3 | 20 |
| Sum | 43 | 17 | 10 | 70 |

Rules
All participants should adhere to the following rules to be eligible for the challenge.
-
Use of External Resource: For Task I and Task II, external audio data, timestamps, pre- trained models, and other information are not allowed to be used except for AISHELL-1 or acoustic data augmentation data, e.g., Musan, and RIR.
For Task III, any resource is permitted to be used to improve the results. All the external public datasets used should be clearly indicated in the final report. - Prohibition of Test Sets Usage: The use of the test sets in any form of non-compliance is strictly prohibited, including but not limited to using the test sets to fine-tune or train the model.
- Audio Alignment: If the forced alignment is used to obtain frame-level classification labels, the alignment model must be trained on the data allowed by the corresponding task.
- Shallow Fusion: Shallow fusion is allowed to the end-to-end approaches, e.g., LAS, RNNT, and Transformer, but the training data of the language model can only come from the transcripts of the Train set.
- Organizer’s Interpretation: The organizer reserves the right of final interpretation. In cases of special circumstances, the organizer will coordinate the interpretation.
Participants are encouraged to prioritize technological innovation, particularly the exploration of novel model architectures, rather than relying solely on increased data usage.
Registration
Participants must sign up for an evaluation account where they can perform various activities such as registering for the evaluation, as well as uploading the submission and system description.
The registration email must be sent from an official institutional or company email address e.g., edu.cn; a public email address (e.g., 163.com, qq.com, or gmail.com) is not accepted.
Once the account has been created, the registration can be performed online. The registration is free to all individuals and institutes. The regular case is that the registration takes effect immediately, but the organizers may check the registration information and ask the participants to provide additional information to validate the registration.
To sign up for an evaluation account, please click Quick Registration.
Submission and Leaderboard
Participants should submit their results via the submission system. Once the submission is completed, it will be shown in the Leaderboard, and all participants can check their positions.
For each task, participants can submit their results no more than 3 times a day.
Timeline
- April 4th, 2024 : Registration opens.
- April 10th, 2024 : Training set release.
- April 17th, 2024 : Development set and baseline system release.
- May 27th, 2024 : Test sets audio release and leaderboard for Task I and II open.
- June 10th, 2024 : Leaderboard freeze for Test sets.
- June 20th, 2024 : System report submission.
Organizers
- Rong Gong, StammerTalk, rong.gong@stammertalk.net
- Lei Xie, Professor, Northwestern Polytechnical University (China), lxie@nwpu.edu.cn
- Hui Bu, CEO, AIShell Inc. (China), buhui@aishelldata.com
- Eng Siong Chng, Associate Professor, Nanyang Technological University, Singapore ASESChng@ntu.edu.sg
- Binbin Zhang, Founder, WeNet Open Source Community (China), binbzha@qq.com
- Ming Li, Associate Professor, Duke Kunshan University (China), ming.li369@dukekunshan.edu.cn
- Yong Qin, Professor, College of Computer Science, Nankai University (China), qinyong@nankai.edu.cn
- Jun Du, Associate Professor, University of Science and Technology of China (China), jundu@ustc.edu.cn
- Hongfei Xue, Ph.D Student, Northwestern Polytechnical University (China), hfxue@mail.nwpu.edu.cn
- Jiaming Zhou, Ph.D Student, Nankai University (China), zhoujiaming@mail.nankai.edu.cn
- Xin Xu, AIShell Inc. (China), xuxin@aishelldata.com









Please contact e-mail stutteringspeech@aishelldata.com if you have any queries.
